I have posted a useful article about SQL Server alerts on Code Project. You can view it online at the following link:
Click: SQL Server Alert
Sunday, August 24, 2008
Saturday, August 23, 2008
Google Custom Search (SQL Server)
Whenever you need any information you start Google, type the term and hit enter. The query may be about any dictionary request, engineering problem and everything else in the world.
Now this information on tip is very good as you can search the world very easily. But to find out the relevant information among the result is very difficult. We need a way so that we could search only the specific sites specializing in the specific field. Google introduced a Custom Search option few years back. Using the same provision, I have created a Custom Search for Microsoft SQL Server.
Google Custom Search
Please visit the above search engine to query your specific terms.
Now this information on tip is very good as you can search the world very easily. But to find out the relevant information among the result is very difficult. We need a way so that we could search only the specific sites specializing in the specific field. Google introduced a Custom Search option few years back. Using the same provision, I have created a Custom Search for Microsoft SQL Server.
Google Custom Search
Please visit the above search engine to query your specific terms.
OUTPUT Clause (Composable DML) in SQL Server 2008
Microsoft introduce OUTPUT clause with SQL Server 2005. The OUTPUT clause made it possible to get the information updates resulted from any DML statement executed.
There are few updates using the OUTPUT clause in SQL Server 2008. But before that for those of you who are not acquainted with this OUTPUT clause, I want to discuss a little about this clause.
CREATE TABLE CUSTOMER_TBL
(
CustomerID int PRIMARY KEY IDENTITY,
CustomerName varchar(500)
)
Declare @Mytable table (Name varchar(50))
INSERT INTO CUSTOMER_TBL (CustomerName)
OUTPUT inserted.CustomerName as Naam into @Mytable
VALUES ('New Customer')
SELECT * FROM @Mytable
SELECT Name FROM @Mytable GROUP BY Name
With SQL Server 2008's row constructor, this statement can be used as follows:
Declare @Mytable table (Name varchar(50))
INSERT INTO CUSTOMER_TBL (CustomerName)
OUTPUT inserted.CustomerName as Naam into @Mytable
VALUES
('New Customer'),
('Another New Customer'),
('Third Customer'),
('New Customer')
SELECT * FROM @Mytable
SELECT Name FROM @Mytable GROUP BY Name
With 2008, this OUTPUT clause can do miracles because of composable DML feature provided. Let us define a new table :
CREATE TABLE CUSTOMER_ORDERS
(
CustomerID int PRIMARY KEY IDENTITY,
OrderDetail varchar(200),
CustomerName varchar(500)
)
INSERT INTO CUSTOMER_ORDERS(CustomerName)
Select e.CustName from
(
INSERT INTO CUSTOMER_TBL (CustomerName)
OUTPUT inserted.CustomerName as CustName
VALUES('NewCustomer'),
('Another New Customer'),
('Third Customer'),
('New Customer')
)e
In the above statement, all the new Customer Names inserted as part of the inner INSERT statement are used in the above INSERT statement. Any of these statements may be INSERT, UPDATE or DELETE. If you start the SQL Server Profiler trace then you would certainly admire that it is still an atomic operation.
There are few updates using the OUTPUT clause in SQL Server 2008. But before that for those of you who are not acquainted with this OUTPUT clause, I want to discuss a little about this clause.
CREATE TABLE CUSTOMER_TBL
(
CustomerID int PRIMARY KEY IDENTITY,
CustomerName varchar(500)
)
Declare @Mytable table (Name varchar(50))
INSERT INTO CUSTOMER_TBL (CustomerName)
OUTPUT inserted.CustomerName as Naam into @Mytable
VALUES ('New Customer')
SELECT * FROM @Mytable
SELECT Name FROM @Mytable GROUP BY Name
With SQL Server 2008's row constructor, this statement can be used as follows:
Declare @Mytable table (Name varchar(50))
INSERT INTO CUSTOMER_TBL (CustomerName)
OUTPUT inserted.CustomerName as Naam into @Mytable
VALUES
('New Customer'),
('Another New Customer'),
('Third Customer'),
('New Customer')
SELECT * FROM @Mytable
SELECT Name FROM @Mytable GROUP BY Name
With 2008, this OUTPUT clause can do miracles because of composable DML feature provided. Let us define a new table :
CREATE TABLE CUSTOMER_ORDERS
(
CustomerID int PRIMARY KEY IDENTITY,
OrderDetail varchar(200),
CustomerName varchar(500)
)
INSERT INTO CUSTOMER_ORDERS(CustomerName)
Select e.CustName from
(
INSERT INTO CUSTOMER_TBL (CustomerName)
OUTPUT inserted.CustomerName as CustName
VALUES('NewCustomer'),
('Another New Customer'),
('Third Customer'),
('New Customer')
)e
In the above statement, all the new Customer Names inserted as part of the inner INSERT statement are used in the above INSERT statement. Any of these statements may be INSERT, UPDATE or DELETE. If you start the SQL Server Profiler trace then you would certainly admire that it is still an atomic operation.
MERGE Statement SQL Server 2008
Though it is very difficult for SQL Server developers to appreciate this is one of the greatest enhancement made in T-SQL in SQL Server 2008. The reason it is difficult to be appreciated from sQL server developer is that in T-SQL they have this FROM clause in UPDATE statement. But for the sake of clarity, I want to make it clear that this FROM clause has never been part of ANSI SQL. Now get this FROM clause out of your all UPDATE statements and try to redo some of your solutions using plain UPDATE statements. Sometimes you would find it nearly impossible. In all those conditions, MERGE statement can rescue you.
For the sake of simplicity, we work out an example. Let us have two tables with the following definitions.
CREATE TABLE CUSTOMER_TBL
(
CustomerID int PRIMARY KEY IDENTITY,
CustomerName varchar(500)
)
CREATE TABLE CUSTOMER_ORDERS
(
CustomerID int PRIMARY KEY IDENTITY,
OrderDetail varchar(200),
CustomerName varchar(500)
)
The greatest example of MERGE statement is a scenario in which there are two tables; One is a source table and the other is the target table. All the rows in the source table which has a record with matching keys in child tables, the information in the source tables are needed to be updated.
MERGE INTO CustomerOrders c
USING CustomerTable t on c.CustomerID = t.CustomerID
WHEN matched then update
set c.CustomerName = t.CustomerName
WHEN not matched then
INSERT (CustomerName) values (t.CustomerName)
WHEN source not matched then delete
The greatest thing is that all of these INSERT, UPDATE and DELETE operations are atomic in totality as a single MERGE statement being executed.
For the sake of simplicity, we work out an example. Let us have two tables with the following definitions.
CREATE TABLE CUSTOMER_TBL
(
CustomerID int PRIMARY KEY IDENTITY,
CustomerName varchar(500)
)
CREATE TABLE CUSTOMER_ORDERS
(
CustomerID int PRIMARY KEY IDENTITY,
OrderDetail varchar(200),
CustomerName varchar(500)
)
The greatest example of MERGE statement is a scenario in which there are two tables; One is a source table and the other is the target table. All the rows in the source table which has a record with matching keys in child tables, the information in the source tables are needed to be updated.
MERGE INTO CustomerOrders c
USING CustomerTable t on c.CustomerID = t.CustomerID
WHEN matched then update
set c.CustomerName = t.CustomerName
WHEN not matched then
INSERT (CustomerName) values (t.CustomerName)
WHEN source not matched then delete
The greatest thing is that all of these INSERT, UPDATE and DELETE operations are atomic in totality as a single MERGE statement being executed.
Friday, August 22, 2008
Performance Improvement of SQL Server
In the very early ages we used to say that "Information is virtue" then it changed to "Information is power". In the present age of information technology, Information is not power any more because information is every where. It is the correct and timely use of it. Just take an example, there are two recruitment agencies both have unlimited resumes of job seekers in their database. Now an organization reaches to both of them and asked them to provide list of candidate suiting a particular criteria. Now the firm which has the faster mechanism to fetch the information from the database would be able to get the contract. So in the present age, only those organizations would remain to be existent which have faster access to information. This is "Survival of the fastest" scenario for an organizational market.
Today I want to discuss many things for you to improve the performance of your SQL Server based systems.
Hardware:
Use Faster Storage Technologies:
It is true that by writing efficient code, we can improve the performance. But this code has to run on hardware, so by using the efficient hardware, we can improve the performance of our systems. These days, we are using multi core processors and primary memory up to many giga bits per second. But the problem is that our database systems are based on the data stored in our persistent storage drives. The maximum speed of such devices is 7200 rpm. This proves to be a bottleneck. But being a software person, we are not concerned, generally, with the speed of our hard drives. But by just using a storage which becomes more responsive to the data requirements of our system, we can improve our systems many folds.
Having discussed about this, a question pops up in our minds. Can we increase the speed of our hard drives? The answer is YES. This can be done by using the drives which have higher speeds. Gone are the days in which the organizations had to use the magnetic storage drives because of their capacity, cost and reliability. These days’ organizations are moving towards solid state options for persistent storage. This storage have more random access ability. So they can process data much faster then their magnetic counterparts.
The only problem is that, these drives are not marketed as they deserve to be. But being an enthusiast, we should dig the technology to get the best out of it.
Software:
a. Efficient use of indexes
First thing first, Index does not mean improving performance for every operation. If there are more SELECT operations in a table, use index on columns. But if there are more inserts / updates / deletes, don't consider implementing it. This is because this would further slow down the process. These operations would not only be slow but would also create fragmentation problems.
b.Computed Columns:
This is another decision you have to take based on your scenarios. If you have more Insert / Updates then using computed columns would significantly reduce the performance of your system. Instead if your system involves more SELECT operations then use of computed columns would prove to be a step towards drastic performance improvement for your system.
c. Selecting the data types of columns in a table
This aspect is sometimes ignored whenever an improvement is discussed. Always consider the following points whenever you have to select a data type of one of your column.
• You should have very good reason not to use non-Unicode VARCHAR if you have to deal with character data. The reasons may be your requirement to store data more than 8000 bytes. There may be special Unicode characters which you have to use. Otherwise, you can do very fine with this data type.
• Always remember that integer based columns are much faster to sort any result set if used in an ORDER BY clause.
• Never use Text or BigInt data types unless you need extra storage.
• Using Integer based data type for Primary key would improve the performance compared to text based or floating point based ones.
d. Bulk Insert / Updates
Whenever Bulk Insert or updates are involved, selecting the recovery model to FULL or BULK LOGGED would slow down the process of the insert or update operation. So what you can do is that you change the recover model do your operation and then change the model back to the previous one.
Index could also create delay for these operations.
Always try to pass data as XML to your stored procedures and use OPENXML for BULK INSERT or UPDATE. This operation is then done through a single INSERT / UPDATE statement as a SET based operation. Avoid using DataAdapter's for update even if you are using updateBatchSize with it. This is because of the reasons: it is not SET based; still more than one UPDATE statements are passed to the SQL Server. This only decreases the roundtrip between your application and SQL Server. The numbers of UPDATE statements being executed on the server are the same. The maximum value for UPDATEBATCHSIZE is a limited value. But with XML option you can send the complete data of a DataTable.
e. Parameterized queries
You might have studied that compiled queries run faster. This is because the DBMS does not have to create a plan for the query for each operation. This also would help you as a precaution against SQL Injection attacks.
f. Stored procedures
Stored procedures also help in preventing the SQL Injection attacks. They also decrease the roundtrips between application and Database Server because many statements are combined in one procedure. This makes these bunch of statements as a single transaction. There are also many other benefits. But the specified ones are enough to use them as a first priority.
g. Stop lavishing use of explicit Cursors
This has been said by so many people so many times that this repetition is certainly not very necessary. I just tell you my example. Few years back I was given a stored procedure in which the previous developer had the lavishing use of the explicitly cursors. The execution time has risen to 40 minutes then because of increase of data in the database. This was expected to increase more as the data increases. By just replacing these cursors with some SET based operations; I was able to turn that execution time to 3 seconds. This was a great achievement on my part. By just looking at this example, you can find out that use of cursor is killing for the performance of your system.
Today I want to discuss many things for you to improve the performance of your SQL Server based systems.
Hardware:
Use Faster Storage Technologies:
It is true that by writing efficient code, we can improve the performance. But this code has to run on hardware, so by using the efficient hardware, we can improve the performance of our systems. These days, we are using multi core processors and primary memory up to many giga bits per second. But the problem is that our database systems are based on the data stored in our persistent storage drives. The maximum speed of such devices is 7200 rpm. This proves to be a bottleneck. But being a software person, we are not concerned, generally, with the speed of our hard drives. But by just using a storage which becomes more responsive to the data requirements of our system, we can improve our systems many folds.
Having discussed about this, a question pops up in our minds. Can we increase the speed of our hard drives? The answer is YES. This can be done by using the drives which have higher speeds. Gone are the days in which the organizations had to use the magnetic storage drives because of their capacity, cost and reliability. These days’ organizations are moving towards solid state options for persistent storage. This storage have more random access ability. So they can process data much faster then their magnetic counterparts.
The only problem is that, these drives are not marketed as they deserve to be. But being an enthusiast, we should dig the technology to get the best out of it.
Software:
a. Efficient use of indexes
First thing first, Index does not mean improving performance for every operation. If there are more SELECT operations in a table, use index on columns. But if there are more inserts / updates / deletes, don't consider implementing it. This is because this would further slow down the process. These operations would not only be slow but would also create fragmentation problems.
b.Computed Columns:
This is another decision you have to take based on your scenarios. If you have more Insert / Updates then using computed columns would significantly reduce the performance of your system. Instead if your system involves more SELECT operations then use of computed columns would prove to be a step towards drastic performance improvement for your system.
c. Selecting the data types of columns in a table
This aspect is sometimes ignored whenever an improvement is discussed. Always consider the following points whenever you have to select a data type of one of your column.
• You should have very good reason not to use non-Unicode VARCHAR if you have to deal with character data. The reasons may be your requirement to store data more than 8000 bytes. There may be special Unicode characters which you have to use. Otherwise, you can do very fine with this data type.
• Always remember that integer based columns are much faster to sort any result set if used in an ORDER BY clause.
• Never use Text or BigInt data types unless you need extra storage.
• Using Integer based data type for Primary key would improve the performance compared to text based or floating point based ones.
d. Bulk Insert / Updates
Whenever Bulk Insert or updates are involved, selecting the recovery model to FULL or BULK LOGGED would slow down the process of the insert or update operation. So what you can do is that you change the recover model do your operation and then change the model back to the previous one.
Index could also create delay for these operations.
Always try to pass data as XML to your stored procedures and use OPENXML for BULK INSERT or UPDATE. This operation is then done through a single INSERT / UPDATE statement as a SET based operation. Avoid using DataAdapter's for update even if you are using updateBatchSize with it. This is because of the reasons: it is not SET based; still more than one UPDATE statements are passed to the SQL Server. This only decreases the roundtrip between your application and SQL Server. The numbers of UPDATE statements being executed on the server are the same. The maximum value for UPDATEBATCHSIZE is a limited value. But with XML option you can send the complete data of a DataTable.
e. Parameterized queries
You might have studied that compiled queries run faster. This is because the DBMS does not have to create a plan for the query for each operation. This also would help you as a precaution against SQL Injection attacks.
f. Stored procedures
Stored procedures also help in preventing the SQL Injection attacks. They also decrease the roundtrips between application and Database Server because many statements are combined in one procedure. This makes these bunch of statements as a single transaction. There are also many other benefits. But the specified ones are enough to use them as a first priority.
g. Stop lavishing use of explicit Cursors
This has been said by so many people so many times that this repetition is certainly not very necessary. I just tell you my example. Few years back I was given a stored procedure in which the previous developer had the lavishing use of the explicitly cursors. The execution time has risen to 40 minutes then because of increase of data in the database. This was expected to increase more as the data increases. By just replacing these cursors with some SET based operations; I was able to turn that execution time to 3 seconds. This was a great achievement on my part. By just looking at this example, you can find out that use of cursor is killing for the performance of your system.
Certified Scrum Master (Shujaat)
After completion of my two days training of Scrum, finally I am a Certified Scrum Master. You can view my profile on the following link:
http://www.scrumalliance.org/profiles/37693-muhammad-shujaat-siddiqi
http://www.scrumalliance.org/profiles/37693-muhammad-shujaat-siddiqi
Wednesday, August 20, 2008
IN Clause (SQL Server)
Today I want to discuss one thing about IN clause in SQL Server.
SELECT * from
tblcustomer
WHERE
(ID, Name) in (
select CustomerID, CustomerName from tblCustomerOrders
)
In the above statement, we wanted to list the details of customers who have submitted some orders. When you run this statement in SQL Server (with the tables tblCustomer and tblCustomerOrders already created), an error is generated about this. The real reason is that SQL Server does not support more than one parameters in the IN clause.
SELECT * from
tblcustomer
WHERE
(ID, Name) in (
select CustomerID, CustomerName from tblCustomerOrders
)
In the above statement, we wanted to list the details of customers who have submitted some orders. When you run this statement in SQL Server (with the tables tblCustomer and tblCustomerOrders already created), an error is generated about this. The real reason is that SQL Server does not support more than one parameters in the IN clause.
Monday, August 18, 2008
Compound Assignment Operators (SQL Server 2008)
Like other .net programming languages compound assignment operators are introduced in SQL Server 2008. If you want to do any basic arithmatic operation (+, -, *, /, %) with any variable and simultaneously assign it to the variable then this proves to be easier in implementation.
DECLARE @MyIntVar INT = 4
SET @myINTVar += 2
SELECT @myINTVar
DECLARE @MyIntVar INT = 4
SET @myINTVar += 2
SELECT @myINTVar
Inline Initialization of Variables in SQL Server 2008
Before 2008, variables could only be assigned with a value using SELECT or SET statements. There was no way to assign any value to a variable at the time when it is declared. With 2008, Microsoft has removed this shortcoming and introduced this feature. This inline initialization can be done using literal or any function.
E.g.
DECLARE @myINTVar INT = 3
DECLARE @myVARCHARVar VARCHAR = LEFT('Shujaat',1)
SELECT @myINTVar, @myVARCHARVar
E.g.
DECLARE @myINTVar INT = 3
DECLARE @myVARCHARVar VARCHAR = LEFT('Shujaat',1)
SELECT @myINTVar, @myVARCHARVar
Table Valued Constructors using VALUES clause
From Today onwards, I am starting a series of Article concerning new T-SQL features introduced in SQL Server 2008. The first article of this series is as under:
Before 2008, when more than one rows were to be inserted using INSERT statement, then more than one INSERT statements were required. But with SQL Server 2008, it is not necessary because only one INSERT statement would do the work. Consider a table with three columns ID, Name and Address.
CREATE TABLE TblCustomer
(
ID int PRIMARY KEY IDENTITY,
Name VARCHAR(30),
Address varchar(45)
)
The single INSERT statement is as under:
INSERT INTO TblCustomer(Name, [Address] )
VALUES ('Shujaat', 'New Jersey'),
('Siddiqi', 'California'),
('Shahbaz', 'Los Angeles')
This can also be used for bulk insert requirements because of its atomic nature. After creating this statement in you .net code, you may pass this statement to the database. This INSERT statement is an atomic operation so there aren’t three statements being executed but only single statements in executed in the database.
This constructor may also be used for SELECT and MERGE statements. The example is as follows:
SELECT VendorID, VendorName
FROM
(
VALUES(1, 'Shujaat'),
(2, 'Siddiqi')
) AS Vendor(VendorID, VendorName)
Before 2008, when more than one rows were to be inserted using INSERT statement, then more than one INSERT statements were required. But with SQL Server 2008, it is not necessary because only one INSERT statement would do the work. Consider a table with three columns ID, Name and Address.
CREATE TABLE TblCustomer
(
ID int PRIMARY KEY IDENTITY,
Name VARCHAR(30),
Address varchar(45)
)
The single INSERT statement is as under:
INSERT INTO TblCustomer(Name, [Address] )
VALUES ('Shujaat', 'New Jersey'),
('Siddiqi', 'California'),
('Shahbaz', 'Los Angeles')
This can also be used for bulk insert requirements because of its atomic nature. After creating this statement in you .net code, you may pass this statement to the database. This INSERT statement is an atomic operation so there aren’t three statements being executed but only single statements in executed in the database.
This constructor may also be used for SELECT and MERGE statements. The example is as follows:
SELECT VendorID, VendorName
FROM
(
VALUES(1, 'Shujaat'),
(2, 'Siddiqi')
) AS Vendor(VendorID, VendorName)
Saturday, August 16, 2008
.net framework 3.5 client profile
Why do I need to install complete framework when I need a few of the things I require to run my application. The good news is that we don’t need to do it anymore. This is because Microsoft has released Client Profile for .net 3.5.
The components includes in the Client profile are as follows:
1. Common Language Runtime
2. ClickOnce
3. Windows Forms
4. Windows Presentation Foundation
5. Windows Communication Foundation
Now you must be wondering if I have this profile installed then would I be able to install complete framework if at some later time I would want to upgrade the machine. Then the answer is YES.
But how should I prepare my project so as to target the Client Profile. Can I target to Client Profile as I target 2.0, 3.0 or 3.5 in my project settings? The answer is ‘Yes’. For a windows application take properties of your project. Go to ‘Compile’ tab and Click ‘Advanced Compile Option’ button. The following dialog box appears:
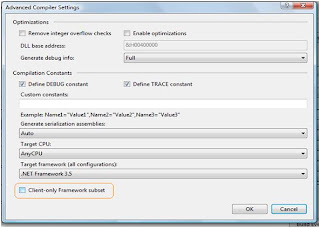
Now what would happen if I use any assembly which is not part of the profile? This would not be taken as ‘Error’ but this comes as ‘Warning’.
On the Client machine, you would have to install Client profile. The download is available on Microsoft download center. It must be remembered that Client profile based applications can be installed with Windows Installer or ClickOnce.
The components includes in the Client profile are as follows:
1. Common Language Runtime
2. ClickOnce
3. Windows Forms
4. Windows Presentation Foundation
5. Windows Communication Foundation
Now you must be wondering if I have this profile installed then would I be able to install complete framework if at some later time I would want to upgrade the machine. Then the answer is YES.
But how should I prepare my project so as to target the Client Profile. Can I target to Client Profile as I target 2.0, 3.0 or 3.5 in my project settings? The answer is ‘Yes’. For a windows application take properties of your project. Go to ‘Compile’ tab and Click ‘Advanced Compile Option’ button. The following dialog box appears:

Now what would happen if I use any assembly which is not part of the profile? This would not be taken as ‘Error’ but this comes as ‘Warning’.
On the Client machine, you would have to install Client profile. The download is available on Microsoft download center. It must be remembered that Client profile based applications can be installed with Windows Installer or ClickOnce.
Thursday, August 14, 2008
Visual Studio 2008 Remote Debugger
With all the great additions Visual Studio team has introduced, there is one more tool which has not gain the attention that it deserves. This tool is Remote Debugger.
Since it talks about remote stuff so there must be some host computer running the debugger and there must be a remote computer running the application. The Debugging monitor (msvmon.exe) is installed on the remote computer. This remote process is then attached to the host computer through Visual Studio 2008 for debugging.
Host computer: Running debugger (Visual Studio 2008)
Remote Computer: Running application to debug and debug monitor (msvmon.exe)
There are two tool installed when Visual Studio 2008 Remote debugger is installed. They are as follows:
1. Visual Studio 2008 Remote Debugger Configuration Wizard
2. Visual Studio 2008 Remote Debugger
The remote debugger is configured through Visual Studio 2008 Remote Debugger Configuration Wizard. This is a separate utility. This tool allows us to specify how remote debugger should be run. Specifically all these questions are answered using this tool.
There are two options to run Remote Debugger.
1. as a service
2. as Windows application
Generally, the first option is used for server applications like ASP.net. Using this option, the one doesn't have to login on the server. We have to specify the username and password whose privileges this service would be using. Since the service is always running, it is not recommended for client applications as it will be always running if this option is used.
Remote debugger also requires some ports to be unblocked. The ports are as follows:
1. TCP port 135 (Used for DCOM)
2. UDP port 450 or 500)
The configuration should allow the remote debugger that it could receive relevant information from the network. There are two options:
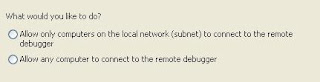
The second option would allow the application debugging from outside the local network. This is an excellent option if we want to debug our application running on client side right from our office thousands of miles apart. This is very good option for organizations involved in off-shore development.
Surely we don’t want anyone else to start debugging our application. There are two options for this:
1. We can specify whether this feature is only available to all the users belonging to our local network or debugger may come through a public network. This is configured using Remote Debugger Configuration utility).
2. We can also specify which users / groups have permissions to run the debugger. As shown in the figure:
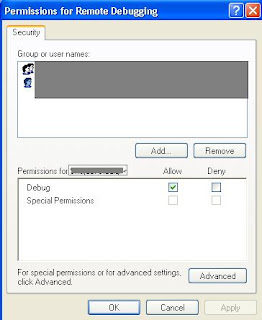
So this security arrangement is very refined. We can not define rights based on the applications i.e. we can not specify that it can debug Application1 and Application2 but he can not debug Application3.
The remote debugger is not supported in any edition of Visual Web Developer. For the visual studio, it is only supported in Pro and Team editions. This means you cannot run this on Express or Standard editions of Visual Studio 2008.
If your operating system is not configured properly, then the following error message appears:
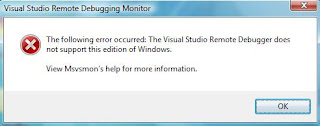
There are a few questions to answer. The answers will prove to be the configuration setting of the remote debugger feature. The questions are as follows:
1. Should it be running as a service or an application?
2. Will the users on the local network would be debugging application or from any public network?
3. What changes in the network security would be required to allow this?
Since it talks about remote stuff so there must be some host computer running the debugger and there must be a remote computer running the application. The Debugging monitor (msvmon.exe) is installed on the remote computer. This remote process is then attached to the host computer through Visual Studio 2008 for debugging.
Host computer: Running debugger (Visual Studio 2008)
Remote Computer: Running application to debug and debug monitor (msvmon.exe)
There are two tool installed when Visual Studio 2008 Remote debugger is installed. They are as follows:
1. Visual Studio 2008 Remote Debugger Configuration Wizard
2. Visual Studio 2008 Remote Debugger
The remote debugger is configured through Visual Studio 2008 Remote Debugger Configuration Wizard. This is a separate utility. This tool allows us to specify how remote debugger should be run. Specifically all these questions are answered using this tool.
There are two options to run Remote Debugger.
1. as a service
2. as Windows application
Generally, the first option is used for server applications like ASP.net. Using this option, the one doesn't have to login on the server. We have to specify the username and password whose privileges this service would be using. Since the service is always running, it is not recommended for client applications as it will be always running if this option is used.
Remote debugger also requires some ports to be unblocked. The ports are as follows:
1. TCP port 135 (Used for DCOM)
2. UDP port 450 or 500)
The configuration should allow the remote debugger that it could receive relevant information from the network. There are two options:

The second option would allow the application debugging from outside the local network. This is an excellent option if we want to debug our application running on client side right from our office thousands of miles apart. This is very good option for organizations involved in off-shore development.
Surely we don’t want anyone else to start debugging our application. There are two options for this:
1. We can specify whether this feature is only available to all the users belonging to our local network or debugger may come through a public network. This is configured using Remote Debugger Configuration utility).
2. We can also specify which users / groups have permissions to run the debugger. As shown in the figure:

So this security arrangement is very refined. We can not define rights based on the applications i.e. we can not specify that it can debug Application1 and Application2 but he can not debug Application3.
The remote debugger is not supported in any edition of Visual Web Developer. For the visual studio, it is only supported in Pro and Team editions. This means you cannot run this on Express or Standard editions of Visual Studio 2008.
If your operating system is not configured properly, then the following error message appears:

There are a few questions to answer. The answers will prove to be the configuration setting of the remote debugger feature. The questions are as follows:
1. Should it be running as a service or an application?
2. Will the users on the local network would be debugging application or from any public network?
3. What changes in the network security would be required to allow this?
Tuesday, August 12, 2008
Midori ( A non-windows operating system by Microsoft)
Today I want to discuss something about a Microsoft Operating system which is still in its nuance. No! It is not a new version of Windows. The codename for the operating system is Midori. This is successor of Microsoft's other Operating system which was named as Singularity. Singularity is available for download for free on Microsoft website. Compared to Singularity, this would not be a research project but a complete commercial operating system project.
With the advent of Web 2.0 and Cloud computing, this is all about sharing. This could be sharing of pictures, movies, games. But this could also be sharing of resources to make systems having capabilities which no one has ever thought of.
Midori is designed to be the future of Cloud computing. This would be a whole new operating system with architecture different from Windows. The architecture is named as Asynchronous Promise Architecture. The local and distributed resource would not be different for applications to consume. It is a net centric, component based operating system which is designed for connected systems. This would be completely developed in managed code. This would not depend upon the application installed on local systems. The hardware, on which the OS is run, would also not be a dependency. It is said that the core principal of Midori's design would be concurrency. This
would be an asynchronous only architecture designed for task concurrency
and parallel use of resources (both local and distributed). This would also
support different topologies, like Client-Server, Peer-to-Peer, multi-tier,
forming a heterogeneous mesh.
It appears that the operating system would be based on Service Oriented architecture with different components scattered in the cloud providing different services to the operating systems. Some say that the objects would be immutable like String in .net.
The kernel would be divided into two parts. One is Micro Kernel which is non-managed. This layer would be encapsulated in a managed Kernel services layer which would provide other functionalities. The scheduling framework is called Resource Management Infrastructure (RMI). This is a power based scheduler to support mobile devices.
The one thing that Microsoft will have to focus on is the co-existence of this new system with Microsoft Windows and applications designed to run on it. May be a runtime is provided just to support the applications designed to run on Microsoft Windows. When I am saying this, I mean COM based applications because managed applications would have no problem in running on a new CLR designed for Midori like we have MONO for Linux. So it can be seen that the applications software running on this, would be coded in .net languages.
Let's wait for the interesting things Microsoft releases about this new Operating System.
With the advent of Web 2.0 and Cloud computing, this is all about sharing. This could be sharing of pictures, movies, games. But this could also be sharing of resources to make systems having capabilities which no one has ever thought of.
Midori is designed to be the future of Cloud computing. This would be a whole new operating system with architecture different from Windows. The architecture is named as Asynchronous Promise Architecture. The local and distributed resource would not be different for applications to consume. It is a net centric, component based operating system which is designed for connected systems. This would be completely developed in managed code. This would not depend upon the application installed on local systems. The hardware, on which the OS is run, would also not be a dependency. It is said that the core principal of Midori's design would be concurrency. This
would be an asynchronous only architecture designed for task concurrency
and parallel use of resources (both local and distributed). This would also
support different topologies, like Client-Server, Peer-to-Peer, multi-tier,
forming a heterogeneous mesh.
It appears that the operating system would be based on Service Oriented architecture with different components scattered in the cloud providing different services to the operating systems. Some say that the objects would be immutable like String in .net.
The kernel would be divided into two parts. One is Micro Kernel which is non-managed. This layer would be encapsulated in a managed Kernel services layer which would provide other functionalities. The scheduling framework is called Resource Management Infrastructure (RMI). This is a power based scheduler to support mobile devices.
The one thing that Microsoft will have to focus on is the co-existence of this new system with Microsoft Windows and applications designed to run on it. May be a runtime is provided just to support the applications designed to run on Microsoft Windows. When I am saying this, I mean COM based applications because managed applications would have no problem in running on a new CLR designed for Midori like we have MONO for Linux. So it can be seen that the applications software running on this, would be coded in .net languages.
Let's wait for the interesting things Microsoft releases about this new Operating System.
ClickOnce - Restore Application to previous state
ClickOnce is often looked as a feature to make deployment easier. It is not generally seen from a user's perspective. If you see it from user's perspective then you would find out that it is also beneficial for user.
When an application is installed through ClickOnce then user has full control over reverting back to earlier version if he / she thinks that the current version should have not been installed. To do this user just has to go to Control Panel. Select the software and click Uninstall. As shown in the picture below, the user is asked about his selection whether he wants to completely uninstall the application or he wants to restore to the previous version.
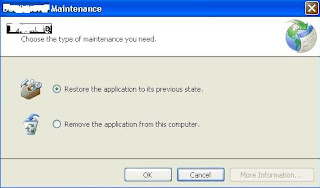
When an application is installed through ClickOnce then user has full control over reverting back to earlier version if he / she thinks that the current version should have not been installed. To do this user just has to go to Control Panel. Select the software and click Uninstall. As shown in the picture below, the user is asked about his selection whether he wants to completely uninstall the application or he wants to restore to the previous version.

Friday, August 8, 2008
Trace .net
Dim TraceTextListner As System.Diagnostics.TextWriterTraceListener = Nothing
Dim traceStream As System.IO.FileStream
traceStream = New System.IO.FileStream("c:\testingissue\test.log", FileMode.Create, FileAccess.Write)
TraceTextListener = New System.Diagnostics.TextWriterTraceListener(traceStream)
System.Diagnostics.Trace.Listeners.Clear()
System.Diagnostics.Trace.Listeners.Add(TraceTextListener)
System.Diagnostics.Trace.Write("Test Trace")
System.Diagnostics.Trace.Flush()
Dim traceStream As System.IO.FileStream
traceStream = New System.IO.FileStream("c:\testingissue\test.log", FileMode.Create, FileAccess.Write)
TraceTextListener = New System.Diagnostics.TextWriterTraceListener(traceStream)
System.Diagnostics.Trace.Listeners.Clear()
System.Diagnostics.Trace.Listeners.Add(TraceTextListener)
System.Diagnostics.Trace.Write("Test Trace")
System.Diagnostics.Trace.Flush()
Friday, August 1, 2008
Joining with a result set returned from a UDF (CROSS AND OUTER APPLY)
I have a function which returns a result set. Now I need to join the result
set with a table in a SELECT query. How can I do that?
This question led me to a feature of T-SQL which is APPLY. This comes in
two flavors. They are as follows:
1. Cross Apply
2. Outer Apply
Both are used to join with the result set returned by a function. Cross
apply works like an INNER JOIN and OUTER apply works like LEFT OUTER JOIN.
set with a table in a SELECT query. How can I do that?
This question led me to a feature of T-SQL which is APPLY. This comes in
two flavors. They are as follows:
1. Cross Apply
2. Outer Apply
Both are used to join with the result set returned by a function. Cross
apply works like an INNER JOIN and OUTER apply works like LEFT OUTER JOIN.
Subscribe to:
Posts (Atom)


